While discussing a problem, Asaf Nachmias, a fellow post doc here, showed me the following trick. Suppose you have a not so well behaved random variable 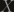 , in the sense that it’s expectation is infinite. Suppose you’ve got a bunch (2:19) of
, in the sense that it’s expectation is infinite. Suppose you’ve got a bunch (2:19) of  , i.i.d. like , what can you say about the distribution of
, i.i.d. like , what can you say about the distribution of 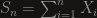 ?
?
Assume that these random variable are non-negative, then binding the probability of  from below is easy: if one of the ‘s is greater then
from below is easy: if one of the ‘s is greater then 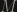 , then so is the sum. This probability is
, then so is the sum. This probability is  , when this last term is small. But is this actually the right order of magnitude?
, when this last term is small. But is this actually the right order of magnitude?
One simple approach is that for the sum to be more then , one of the variables must be at least 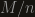 , so
, so 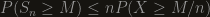 . This is nice, but most of the time it’s not enough. To be specific, in our case we had
. This is nice, but most of the time it’s not enough. To be specific, in our case we had  , so we get
, so we get 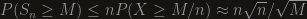 while the lower bound is
while the lower bound is  . It seems pretty obvious that the upper bound could be improved, but how?
. It seems pretty obvious that the upper bound could be improved, but how?
Here’s the trick: if we’re interested in the probability of some variable being more then , we might as well truncate it at . That is, given a random variable , we produce a new, truncated variable  , which is just the minimum of and . This new variable now has a finite expectation, which we can use. First we note that
, which is just the minimum of and . This new variable now has a finite expectation, which we can use. First we note that  . Then, using Markov’s inequality we get
. Then, using Markov’s inequality we get 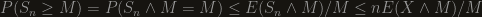 .
.
Is this better? in our specific case, 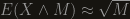 , so the bound we got was
, so the bound we got was  , which matches the lower bound, yey! If we look closely we see that Markov’s inequality implies that
, which matches the lower bound, yey! If we look closely we see that Markov’s inequality implies that 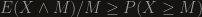 , but in our case we get
, but in our case we get  , so the upper and lower bound match, up to a constant. It’s easy to see that this last condition is slightly stronger then having an infinite expectation, so we can’t expect it to work every time, but even when it’s not true (consider a random variable with
, so the upper and lower bound match, up to a constant. It’s easy to see that this last condition is slightly stronger then having an infinite expectation, so we can’t expect it to work every time, but even when it’s not true (consider a random variable with  ), you usually lose a relatively small factor (in this case
), you usually lose a relatively small factor (in this case 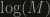 ). Still, sometimes the first, simpler, bound is better (here it is
). Still, sometimes the first, simpler, bound is better (here it is 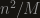 , which is better when
, which is better when  ).
).
Posted in Uncategorized

 . Then, they are either in one hemisphere together, or they are in two complementing hemispheres (or both).
. Then, they are either in one hemisphere together, or they are in two complementing hemispheres (or both). , if we replace the great circle with something shorter, as long as the product of their length is less then
, if we replace the great circle with something shorter, as long as the product of their length is less then  . To see this you only have to realize that the expectation we calculated is actually linear in the length of both curves. In other words, the formula should be
. To see this you only have to realize that the expectation we calculated is actually linear in the length of both curves. In other words, the formula should be 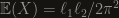 . As long as this is less then 2, we’re fine.
. As long as this is less then 2, we’re fine. with positive probability.
with positive probability.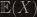 . As always, the expectation is additive, therefore it depends only on the length of the curve and in a linear way. So,
. As always, the expectation is additive, therefore it depends only on the length of the curve and in a linear way. So,  , where
, where  is the length of the curve and
is the length of the curve and  is some constant. To find out what the contant is, just take a curve for which calculating the expectation is easy – a great circle. The length of a great circle is
is some constant. To find out what the contant is, just take a curve for which calculating the expectation is easy – a great circle. The length of a great circle is 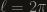 and a uniformly random great circle intersects a great circle at exactely 2 points, almost surely. Therefore
and a uniformly random great circle intersects a great circle at exactely 2 points, almost surely. Therefore 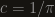 .
. . However,
. However,  , almost surely, so whenever
, almost surely, so whenever  , it is at least 2. This means that the probability of
, it is at least 2. This means that the probability of 
 post.
post.